The Runtime Tradeoff in Vector Search
Vector search tuning is often discussed in terms of index parameters, embedding models, and average recall. In production, though, the runtime tradeoff matters just as much: how much latency you are willing to spend to recover more of the true nearest neighbors.
For HNSW, that tradeoff is controlled by the exploration factor, called ef_search in pgvector.
ef_search defines the size of a list1 accumulated during a search. It holds the candidate documents closest to the query. The search walks the graph and keeps the best candidates it finds. The search is approximate, so the bigger that list, the more of the true top-k you retrieve (i.e. recall) — and the longer the search takes.
ef_search can be set at query time. It’s one of three knobs that trade latency for recall; the other two, m and ef_construction, are fixed when you build the index, so they’re far less flexible.
Vendor guides tell you to tune to average recall [1], which is a good start. But as the Ada-ef paper [2] and others point out, the mean doesn’t account for the skewed shape of the recall distribution.
Besides, for a real production system I’d want a tail-aware SLI that tracks the fraction of queries that actually met the target recall.
In this post I will look at what this one parameter does to recall and latency on two real datasets. Then how to set it, and keep it set.
The test
I pulled two datasets and took 300,000 random documents and 2,000 random queries from each:
- SuperUser — Stack Exchange’s Super User site. The document is the question body, the query is the title.
- Reddit — posts paired with the author’s own TL;DR line. The document is the post, the query is the TL;DR.
These differ in two ways: the domain, and the kind of text the query is — a short title versus a prose summary. That second difference matters later.
I embedded everything with BAAI/bge-small-en-v1.5 (384-dim, normalized), loaded it into pgvector 0.8.2 (HNSW, m=16, ef_construction=64), and computed the exact top-10 for every query by brute force. Then I measured recall and latency across ef_search ∈ {10, 20, 40, 60, 80, 100, 150, 200, 300, 400}.
The full test is in the repo and runs from a single command.
Findings
ef_search doesn’t transfer between workloads
Same target recall, very different ef_search. To hit mean recall@10 = 0.95:
| corpus | ef at mean recall 0.95 | median latency | p90 latency |
|---|---|---|---|
| SuperUser | 48.5 | 0.702 ms | 0.863 ms |
| 126.9 | 1.360 ms | 1.825 ms |
Reddit needs ~2.6× the ef_search SuperUser does — same sample size, same index, same embedding model.
Latency is the same function of ef_search on both corpora; the two curves sit on top of each other (below). It tracks ef_search, not the data. So Reddit, needing ~2.6× the ef_search, pays ~2× the latency for the same recall.
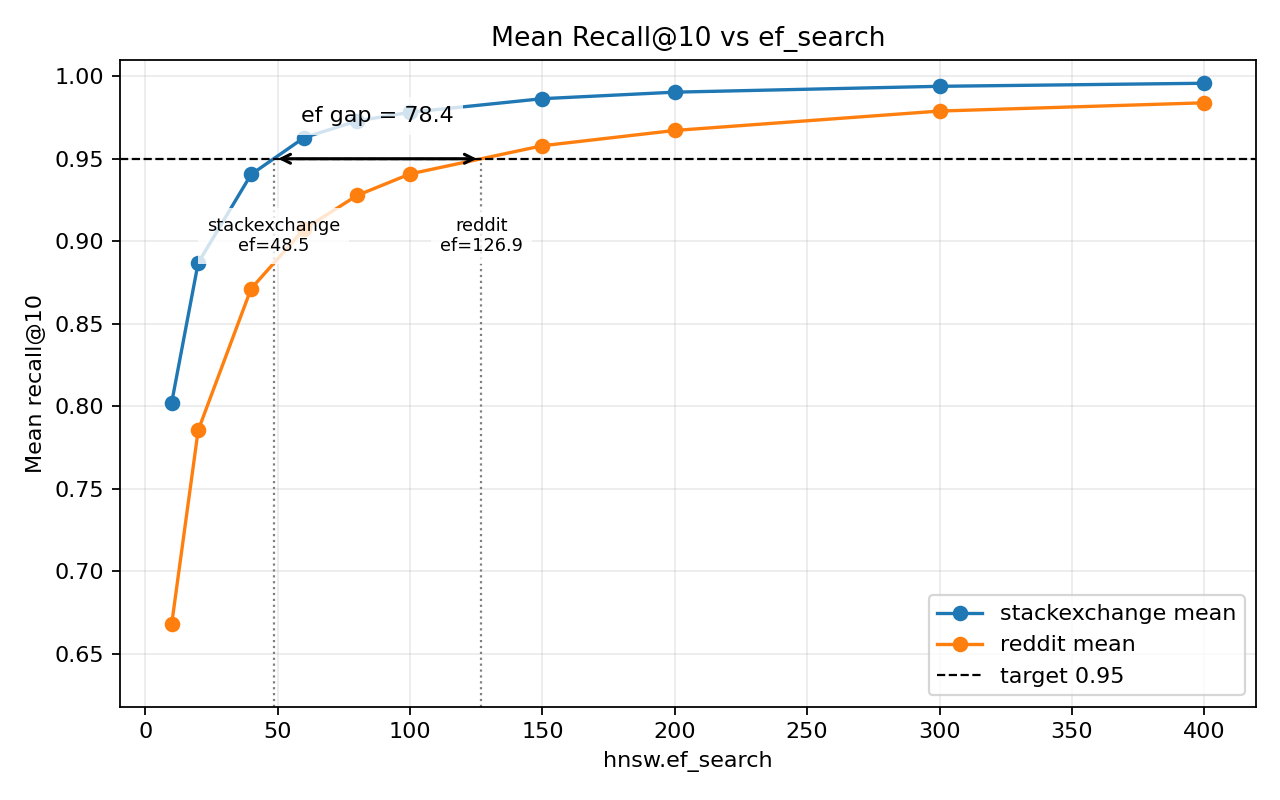
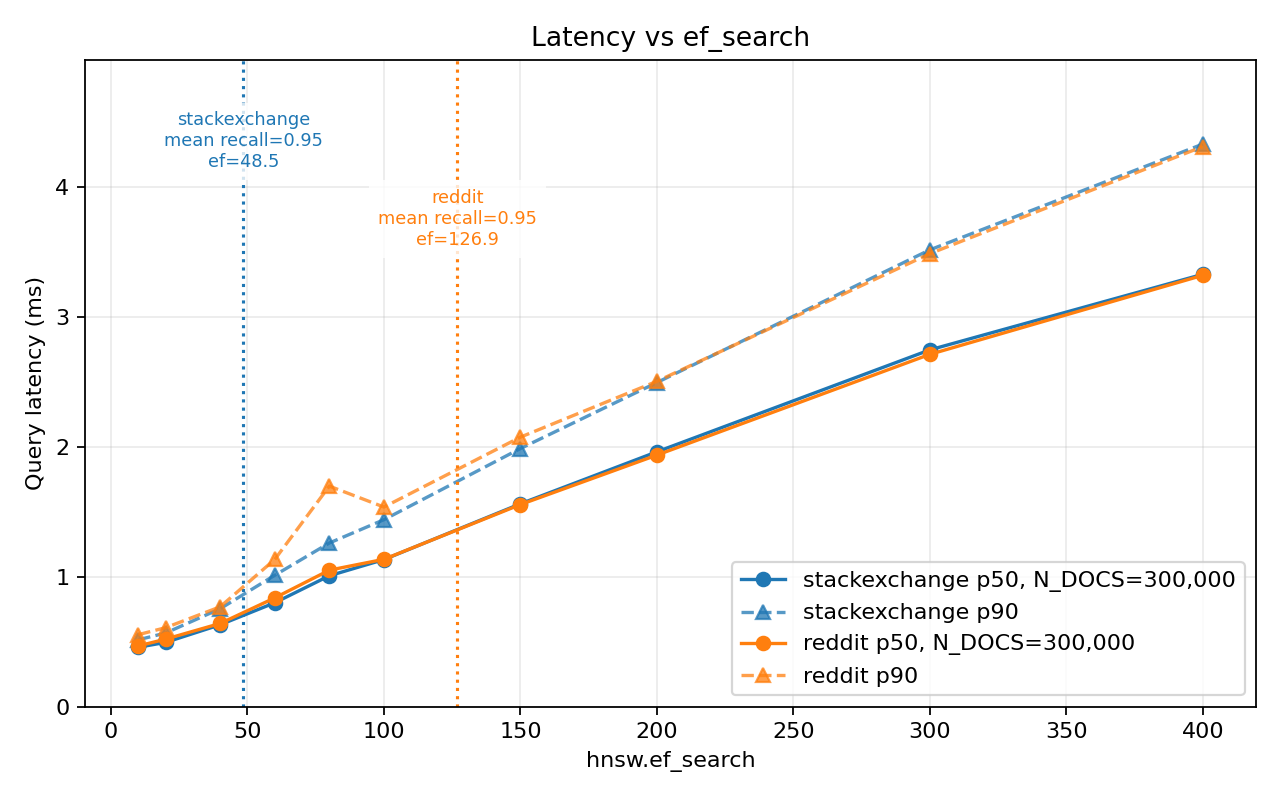
The obvious explanation is embedding geometry — different vectors, different ef_search. That’s part of it. The queries aren’t comparable either: SuperUser queries are titles, Reddit queries are summaries. Different length, different shape, different relationship to the document. So the 2.6× mixes corpus and query type, and this test can’t separate them. It doesn’t change the takeaway: you can’t guess ef_search from a rule of thumb, and you can’t carry it from one workload to the next.
The mean hides the tail
pgvector ships with ef_search = 40. Here’s what that buys, per percentile:
| corpus | mean | p50 | p10 | p05 | below 0.9 |
|---|---|---|---|---|---|
| SuperUser | 0.94 | 1.0 | 0.8 | 0.7 | 13.2% |
| 0.87 | 0.9 | 0.6 | 0.5 | 31.1% |
SuperUser’s mean recall is 0.94. Looks fine. If your target is 0.9, your dashboard is green. But 13% of queries are below it. The bottom 5% return recall 0.7 — they’re missing three of their true top ten.
Reddit is worse. Mean 0.87, a third of queries under 0.9, and the bottom 5% return half their true neighbors.
This is why the mean is the wrong number to tune to. It’s an average over a long tail, and the tail is exactly what a downstream consumer — a reranker, a join, an LLM prompt — feels when results go missing. If you care about that, track the fraction of queries that clear your target, not the average recall.
Calibrating to the tail transfers
If the mean is the wrong target, calibrate to the tail. I split each workload into 1,400 training and 600 test queries, took the smallest ef_search where the bottom 10% of training queries cleared 0.9 recall, and checked it on the held-out 600.
| corpus | ef (p10 ≥ 0.9, train) | test p10 |
|---|---|---|
| SuperUser | 60 | 0.90 |
| 200 | 0.90 |
It holds. The ef_search you pick on a sample clears the same bar on queries it never saw. (Both numbers are higher than the ef_search for mean 0.95 — protecting the bottom decile costs more than nudging the average.)
The recipe is short:
- Sample a few thousand real queries.
- Brute-force their true top-10.
- Sweep
ef_search. - Take the smallest value where your tail percentile clears target on the training split.
- Confirm on a held-out split.
One caveat: it needs scale. I ran the same recipe at 10k docs with a 350/150 split — both workloads picked an ef_search that cleared p10 ≥ 0.9 on training and then missed on test (StackExchange 0.80, Reddit 0.89). The tail percentile is estimated off too few queries to be stable, so it overfits the training split. The held-out check isn’t optional; it’s how you catch this before it ships.
Keeping it set
One number isn’t permanent — query patterns drift, the corpus changes, and last month’s ef_search quietly stops clearing the bar. The fix is the same recipe on a schedule: sample, check the tail, recalibrate when it slips. That’s the case for a single number — it’s one signal you can monitor.
The baseline for now: ef_search doesn’t transfer, the mean hides the tail, and the tail calibrates on a sample.
References
[1] OpenSearch, A practical guide to selecting HNSW hyperparameters.
[2] Zhang & Miller, Distribution-Aware Exploration for Adaptive HNSW Search (Ada-ef), SIGMOD 2026.
-
Technically it’s two heaps — a min-heap of candidates and a max-heap of the current result.
ef_searchbounds the second one. ↩